
Data Analytics & Machine Learning – Billboard Chart Analysis
IEOR 4212 Final Project, Columbia University Python, Pandas, Matplotlib, Scikit-learn, Jupyter Notebooks
One Liner
Analyzed over 50 years of Billboard chart data to identify musical features that predict long-term song popularity, using Python-based data analytics and machine learning techniques.

About The Project
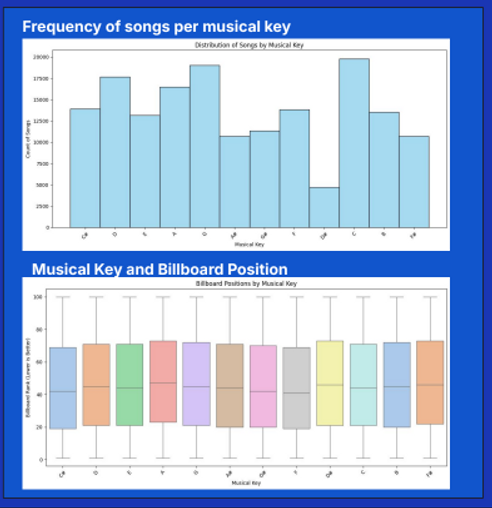
As part of Columbia’s hands-on Data Analytics & Machine Learning course, our group developed an end-to-end data pipeline that cleaned, merged, analyzed, and modeled data from the Billboard Top 100 and Million Songs Dataset. We investigated what musical features (like key, danceability, energy, and tempo) are associated with songs that stay on the charts long-term (>12 weeks).
The project was structured in two parts:
1. Exploratory Data Analysis & Visualization
2. Predictive Modeling using Machine Learning

Technical Approach
-
We wrote the entire pipeline in Python using Jupyter Notebooks, split across two main scripts:
1. Data Cleaning & Visualization
(IEOR_4212_project_Data_Visualization&Analysis.ipynb)
○ Tools: pandas, matplotlib, seaborn, numpy
○ Tasks: dataset merging, NaN handling, groupby/aggregation, MinMax scaling, violin plots, histograms, line graphs
2. Machine Learning Models (IEOR_4212_project_ML_Models.ipynb)
○ Tools: scikit-learn, StandardScaler, train_test_split, GridSearchCV, LogisticRegression, DecisionTreeClassifier ○ Tasks: one-hot encoding for categorical variables (e.g. genre), model training and testing, hyperparameter tuning, evaluation
with metrics like F1-score, precision, and AUC Special attention was paid to handling class imbalance and standardizing features to avoid model bias. Code was organized and well-commented to support peer review and replication.


-
Led data cleaning and normalization across multiple datasets
-
Created visualizations to highlight statistical trends in song attributes and rankings
-
Engineered features and implemented classification models (Logistic Regression, Decision Trees)
-
Tuned hyperparameters with cross-validation and interpreted model performance
-
Co-presented project results and contributed to final written and code deliverables

CHALLENGES
How We Solve Them?
Making music sharing feel truly social:
Data inconsistency across sources
Merging the Billboard dataset (focused on rankings) with the Million Songs dataset (rich in features) required careful matching and filtering. We resolved this by performing an inner join on song + artist and removing duplicates/NaNs.
Feature scaling and bias handling
To avoid skewed model training, we used Min-Max scaling and StandardScaler, and applied one-hot encoding for categorical variables like genre.
Class imbalance
Long-lasting songs were rarer than short-lasting ones. We focused on precision, recall, and F1-score in our model evaluations and used cross-validation to build more reliable classifiers.
OUTCOMES & IMPACT
-
Identified clear correlations between long-lasting Billboard presence and high danceability, energy, and valence
-
Demonstrated that danceability is the strongest predictor of chart success over time
-
Built predictive models with solid accuracy and recall, especially Logistic Regression
-
Gained hands-on experience with the full data science workflow — from scraping and cleaning to visualization and supervised learning
-
Delivered code, slides, and a final presentation rated highly by peers and instructors